

脚手架开发的系统版本是ubuntu22.04-LTS,推荐配置为2核8G,硬盘大小为60GB.读者可自行选择使用虚拟机或云服务器进行开发。 源码链接(随文章进度更新):
https://gitee.com/ly121381/cpp-microservice-scaffold
我们对这些中间件的介绍与使用方法,不需要大家强制记下来,用到的时候忘记了,把文章当作手册再来看就可以了。第一遍就是混个眼熟,知道有这种用法就可以了。 @TOC
一.通过docker获取开发环境
我们这里使用的docker版本为28.4.0,docker-compose版本为2.13.0,推荐使用相同及更高版本进行环境获取。 首先我们先拉取事先准备好的开发环境: 拉取远端仓库:
git clone https://gitee.com/qigezi/dev-environment.git拉取之后的仓库目录结构如下:
xxxxxxxxxxdev@dev-host:~/workspace$ tree -L 3.├── dev-environment│ ├── dev-environment│ │ └── workspace # 开发环境的挂载⽬录│ ├── docker-compose.yml│ ├── icsearch│ │ ├── elasticsearch.yml│ │ └── plugins # 搜索引擎的中⽂分词插件(会⾃动安装)│ ├── kibana│ │ └── kibana.yml│ ├── mysql│ │ ├── my.cnf│ │ └── sql.d│ ├── rabbitmq│ │ ├── 20-management_agent.disable_metrics_collector.conf│ │ └── Dockerfile # ⽬前没⽤到,rabbitmq直接通过连接拉取的镜像│ └── redis│ └── redis.conf该环境的默认用户为dev密码为1,如有需要读者可以自行更改。然后使用命令:
xxxxxxxxxxdocker-compose up -d启动容器环境,因为虚拟环境的端口映射为22:2222,所以我们新开一个ssh链接,改目标端口号为2222即可连接到虚拟开发环境中:
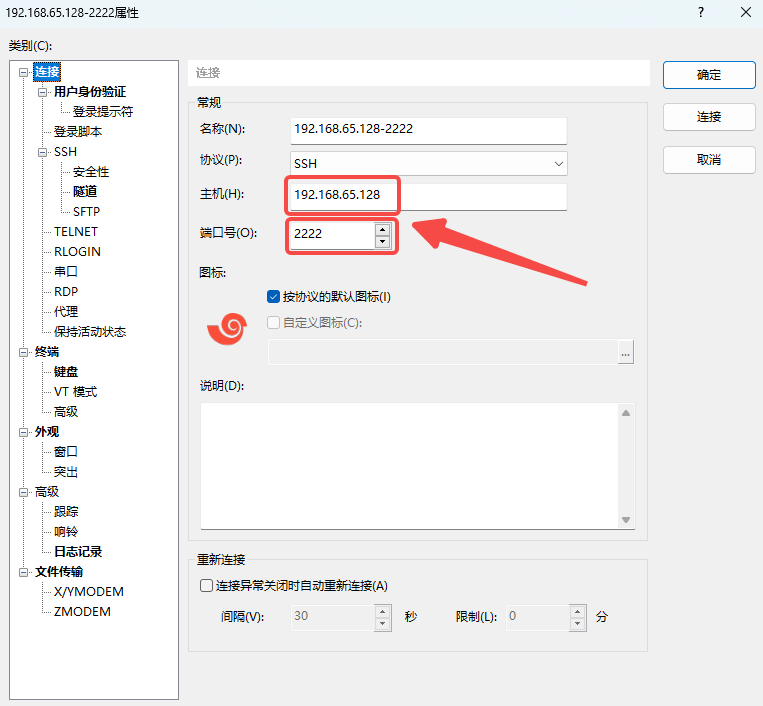 该虚拟环境已经配置好了所有的我们之后会使用到的中间件环境。所以我们接下来按照文章中所说的直接使用即可。不需要再去做额外配置了。大家可自行选择vscode,cursor等开发工具进行接下来的开发。
该虚拟环境已经配置好了所有的我们之后会使用到的中间件环境。所以我们接下来按照文章中所说的直接使用即可。不需要再去做额外配置了。大家可自行选择vscode,cursor等开发工具进行接下来的开发。
二.gflags的介绍使用
gflags是 Google 开发的⼀个开源库,⽤于 C++ 应⽤程序中命令行参数的声明、定义和解析。gflags 库提供了⼀种简单的方式来添加、解析和文档化命令⾏标志(flags),使得程序可以根据不同的运⾏时配置进行调整。 gflags的安装(我们虚拟环境中已经事先安装过,这里不需要再进行安装):
xxxxxxxxxxdev@dev-host:~/workspace/gflags$ sudo apt-get install libgflags-devgflags的使用需要包含以下头文件:
xxxxxxxxxx编译时需要链接库-lgflags
2.1 定义参数
利⽤ gflags 提供的宏定义来定义参数。该宏的3个参数分别为命令⾏参数名,参数默认值,参数的帮助信息。
xxxxxxxxxxDEFINE_bool(reuse_addr, true, "是否开始⽹络地址重⽤选项");DEFINE_int32(log_level, 1, "⽇志等级:1-DEBUG, 2-WARN, 3-ERROR");DEFINE_string(log_file, "stdout", "⽇志输出位置设置,默认为标准输出");DEFINE_string(server_ip, "127.0.0.1", "服务器IP地址");gflags⽀持定义多种类型的宏函数:
xxxxxxxxxxDEFINE_boolDEFINE_int32DEFINE_int64DEFINE_uint64DEFINE_doubleDEFINE_string2.2访问参数
我们可以在程序中通过 FLAGS_reuse_addr 像正常变量⼀样访问标志参数。⽐如在上⾯的例⼦中,我们可以通过 FLAGS_log_level 和 FLAGS_log_file 变量来访问命令⾏参数。
2.3不同文件访问参数
如果想再另外⼀个⽂件访问当前⽂件的参数,以参数 FLAGS_reuse_addr 为例,我们可以使⽤宏 DECLARE_bool(reuse_addr) 来声明引⼊这个参数。其实这个宏就相当于做了 extern FLAGS_reuse_addr, 定义外部链接属性。
2.4初始化所有参数
当我们定义好参数后,需要告诉可执⾏程序去处理解析命令行传入的参数,使得 FLAGS_* 变量能得到正确赋值。我们需要在main函数中,调⽤下⾯的函数来解决命令行传入的所有参数。
xxxxxxxxxxint main(int argc, char *argv[]){ google::ParseCommandLineFlags(&argc, &argv, true); return 0;}argc 和 argv 就是 main 的⼊⼝参数 第三个参数被称为 remove_flags 。如果它为 true , 表示 ParseCommandLineFlags 会从argv 中移除标识和它们的参数,相应减少 argc 的值。如果它为false , ParseCommandLineFlags 会保留 argc 不变,但将会重新调整它们的顺序,使得标识再前⾯。
2.5运行参数设置
gflags为我们提供了多种命令⾏设置参数的⽅式。 string和int等类型设置参数
xxxxxxxxxxexec --log_file="./main.log"exec -log_file="./main.log"exec --log_file "./main.log"exec -log_file "./main.log"对于bool类型额外有一种特殊的设置方法
xxxxxxxxxxexec --reuse_addrexec --noreuse_addrexec --reuse_addr=trueexec --reuse_addr=false2.6配置文件的使用
配置⽂件的使⽤,其实就是为了让程序的运⾏参数配置更加标准化,不需要每次运⾏的时候都⼿动收 ⼊每个参数的数值,⽽是通过配置⽂件,⼀次编写,永久使⽤。 需要注意的是,配置⽂件中选项名称必须与代码中定义的选项名称⼀致,尤其需要注意的是配置⽂件中的字符串数据不需要使⽤双引号。 样例:
xxxxxxxxxx//main.conf-reuse_addr=true-log_level=3-log_file=./log/main.logxxxxxxxxxxexec --flagfile=filename2.7其他特殊参数标识
xxxxxxxxxx--help # 显⽰⽂件中所有标识的帮助信息--helpfull # 和-help ⼀样, 帮助信息更全⾯⼀些--helpshort # 只显⽰当前执⾏⽂件⾥的标志--helpxml # 以 xml ⽅式打印,⽅便处理--version # 打印版本信息,由 google::SetVersionString()设定--flagfile -flagfile=f #从⽂件 f 中读取命令⾏参数2.8样例
x//main.cc
DEFINE_bool(reuse_addr, true, "是否开始⽹络地址重⽤选项");DEFINE_int32(log_level, 1, "⽇志等级:1-DEBUG, 2-WARN, 3-ERROR");DEFINE_string(log_file, "stdout", "⽇志输出位置设置,默认为标准输出");DEFINE_string(server_ip, "127.0.0.1", "服务器IP地址");
int main(int argc, char *argv[]){ google::ParseCommandLineFlags(&argc, &argv, true); std::cout << "reuse: " << FLAGS_reuse_addr << std::endl; std::cout << "reuse: " << FLAGS_log_level << std::endl; std::cout << "reuse: " << FLAGS_log_file << std::endl; std::cout << "reuse: " << FLAGS_server_ip << std::endl; print_server_ip(); return 0;}//test.ccDECLARE_string(server_ip);void print_server_ip() { std::cout << "Server IP: " << FLAGS_server_ip << std::endl;}编译使用到的makfile
xxxxxxxxxxmain: g++ main.cc test.cc -o main -lgflags
clean: rm -f main第一种方式,通过命令行进行参数的设置:
xxxxxxxxxxdev@3b5ab207a0b1:~/workspace/cpp-microservice-scaffold/example/gflags$ ./main exec --log_file="./main.log" --server_ip="192.9.0.1"reuse: 1reuse: 1reuse: ./main.logreuse: 192.9.0.1Server IP: 192.9.0.1可以看到没有设置的使用默认值,其他的与设置值相同。 第二种方式便是通过配置文件进行设置:
xxxxxxxxxx//main.conf-reuse_addr=false-log_level=0-log_file=stdin-server_ip=192.0.2.1xxxxxxxxxxdev@3b5ab207a0b1:~/workspace/cpp-microservice-scaffold/example/gflags$ ./main exec --flagfile=./main.conf reuse: 0reuse: 0reuse: stdinreuse: 192.0.2.1Server IP: 192.0.2.1三.gtest的介绍与使用
GTest是⼀个跨平台的 C++单元测试框架,由google公司发布。gtest是为了在不同平台上为编C++单元测试而⽣成的。它提供了丰富的断⾔、致命和非致命判断、参数化等等测试所需的宏,以及全局测试,单元测试组件。
3.1安装
xxxxxxxxxxdev@dev-host:~/workspace$ sudo apt-get install libgtest-dev3.2使用介绍
3.2.1头文件包含
xxxxxxxxxx3.2.2框架初始化接口
xxxxxxxxxxtesting::InitGoogleTest(&argc, argv);3.2.3调用测试样例
xxxxxxxxxxRUN_ALL_TESTS();3.2.4TEST宏
xxxxxxxxxx//这⾥不需要双引号,且同测试下多个测试样例不能同名TEST(测试名称, 测试样例名称)TEST_F(test_fixture,test_name)TEST:主要⽤来创建⼀个简单测试, 它定义了⼀个测试函数, 在这个函数中可以使⽤任何C++代码并且使⽤框架提供的断⾔进⾏检查 TEST_F:主要⽤来进⾏多样测试,适⽤于多个测试场景如果需要相同的数据配置的情况, 即相同的数据测不同的⾏为
3.2.5断言宏
GTest中的断⾔的宏可以分为两类:
• ASSERT系列:如果当前点检测失败则退出当前函数
• EXPECT系列:如果当前点检测失败则继续往下执⾏
下⾯是经常使⽤的断⾔介绍
xxxxxxxxxx// bool值检查ASSERT_TRUE(参数),期待结果是trueASSERT_FALSE(参数),期待结果是false//数值型数据检查ASSERT_EQ(参数1,参数2),传⼊的是需要⽐较的两个数 equalASSERT_NE(参数1,参数2),not equal,不等于才返回trueASSERT_LT(参数1,参数2),less than,⼩于才返回trueASSERT_GT(参数1,参数2),greater than,⼤于才返回trueASSERT_LE(参数1,参数2),less equal,⼩于等于才返回trueASSERT_GE(参数1,参数2),greater equal,⼤于等于才返回true3.6样例
xxxxxxxxxxTEST(vector, intsert) { std::vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); ASSERT_TRUE(v[0] == 1); ASSERT_EQ(v.size(), 3); ASSERT_NE(v.size(), 4);}
TEST(vector, pop) { std::vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); v.pop_back(); ASSERT_EQ(v.size(), 2); ASSERT_EQ(v.size(), 3); ASSERT_TRUE(v[1] == 2);}
int main(int argc,char* argv[]){ testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();}xxxxxxxxxxdev@3b5ab207a0b1:~/workspace/cpp-microservice-scaffold/example/gtest$ ./simple [==========] Running 2 tests from 1 test suite.[----------] Global test environment set-up.[----------] 2 tests from vector[ RUN ] vector.intsert[ OK ] vector.intsert (0 ms)[ RUN ] vector.popsimple.cc:21: FailureExpected equality of these values: v.size() Which is: 2 3[ FAILED ] vector.pop (0 ms)[----------] 2 tests from vector (0 ms total)
[----------] Global test environment tear-down[==========] 2 tests from 1 test suite ran. (0 ms total)[ PASSED ] 1 test.[ FAILED ] 1 test, listed below:[ FAILED ] vector.pop
1 FAILED TEST你也可以不返回RUN_ALL_TESTS(),因为它就相当于我们程序出问题时返回-1一样,当他有用例不通过时返回的便不为0.所以可以选择返回也可以选择不返回,具体看我们的使用场景。
3.3事件机制
GTest中的事件机制是指在测试前和测试后提供给⽤⼾⾃⾏添加操作的机制,⽽且该机制也可以让同⼀测试套件下的测试⽤例共享数据。GTest框架中事件的结构层次:
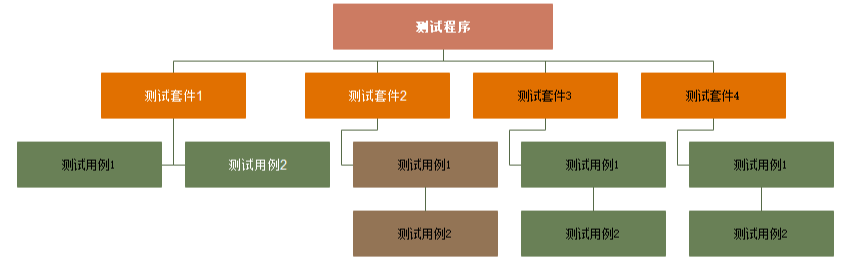 测试程序:⼀个测试程序只有⼀个main函数,也可以说是⼀个可执⾏程序是⼀个测试程序。该级别的事件机制是在程序的开始和结束执⾏
测试套件:代表⼀个测试⽤例的集合体,该级别的事件机制是在整体的测试案例开始和结束执⾏
测试⽤例:该级别的事件机制是在每个测试⽤例开始和结束都执⾏
事件机制的最⼤好处就是能够为我们各个测试⽤例提前准备好测试环境,并在测试完毕后⽤于销毁环境,这样有个好处就是如果我们有⼀端代码需要进⾏多种不同⽅法的测试,则可以通过测试机制在每个测试⽤例进⾏之前初始化测试环境和数据,并在测试完毕后清理测试造成的影响。
GTest提供了三种常⻅的的事件:
测试程序:⼀个测试程序只有⼀个main函数,也可以说是⼀个可执⾏程序是⼀个测试程序。该级别的事件机制是在程序的开始和结束执⾏
测试套件:代表⼀个测试⽤例的集合体,该级别的事件机制是在整体的测试案例开始和结束执⾏
测试⽤例:该级别的事件机制是在每个测试⽤例开始和结束都执⾏
事件机制的最⼤好处就是能够为我们各个测试⽤例提前准备好测试环境,并在测试完毕后⽤于销毁环境,这样有个好处就是如果我们有⼀端代码需要进⾏多种不同⽅法的测试,则可以通过测试机制在每个测试⽤例进⾏之前初始化测试环境和数据,并在测试完毕后清理测试造成的影响。
GTest提供了三种常⻅的的事件:
3.3.1全局事件
如果我们有测试数据需要在所有测试开始前进行初始化在所有测试后进行清理。需要创建⼀个⾃⼰的类,然后继承testing::Environment类,然后分别实现成员函数 SetUp 和 TearDown ,同时在main函数内进⾏调⽤testing::AddGlobalTestEnvironment(new MyEnvironment); 函数添加全局的事件机制:
xxxxxxxxxx// 全局事件:针对整个测试程序,提供全局事件机制,能够在测试之前配置测试环境数据,测试完毕后清理数据// 先定义环境类,通过继承testing::Environment的派⽣类来完成// 重写的虚函数接⼝SetUp会在测试之前被调⽤; TearDown会在测试完毕后调⽤.std::unordered_map<std::string, std::string> dict;class HashTestEnv : public testing::Environment{public: virtual void SetUp() override { std::cout << "测试前:提前准备数据!!\n"; dict.insert(std::make_pair("Hello", "你好")); dict.insert(std::make_pair("hello", "你好")); dict.insert(std::make_pair("雷吼", "你好")); } virtual void TearDown() override { std::cout << "测试结束后:清理数据!!\n"; dict.clear(); }};TEST(hash_case_test, find_test){ auto it = dict.find("hello"); ASSERT_NE(it, dict.end());}TEST(hash_case_test, size_test){ ASSERT_GT(dict.size(), 0);}int main(int argc, char *argv[]){ testing::AddGlobalTestEnvironment(new HashTestEnv); testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();}运行结果:
xxxxxxxxxx[==========] Running 2 tests from 1 test case.[----------] Global test environment set-up.测试前:提前准备数据!![----------] 2 tests from hash_case_test[ RUN ] hash_case_test.find_test[ OK ] hash_case_test.find_test (0 ms)[ RUN ] hash_case_test.size_test[ OK ] hash_case_test.size_test (0 ms)[----------] 2 tests from hash_case_test (0 ms total)[----------] Global test environment tear-down测试结束后:清理数据!![==========] 2 tests from 1 test case ran. (0 ms total)[ PASSED ] 2 tests.3.3.2TestSuite事件
如果说我们想要将多个测试分为不同的组,然后不同的组又各自需要自己的测试环境,需要在每组的测试开始前去初始化环境,结束时清理环境。我们同样需要去创建⼀个类,继承⾃ testing::Test ,实现两个静态函数 SetUpTestCase 和 TearDownTestCase ,测试套件的事件机制不需要像全局事件机制⼀样在 main 注册,⽽是需要将我们平时使⽤的 TEST 宏改为 TEST_F 宏。 SetUpTestCase() 函数是在测试套件第⼀个测试⽤例开始前执⾏ TearDownTestCase() 函数是在测试套件最后⼀个测试⽤例结束后执⾏ 需要注意TEST_F的第⼀个参数是我们创建的类名,也就是当前测试套件的名称,这样在TEST_F宏的测试套件中就可以访问类中的成员了。
xxxxxxxxxx
// TestSuite: 测试套件/集合进行单元测试,即将多个相关测试归入一组的方式进行测试,为这组测试用例进行环境配置和清理// 概念: 对一个功能的验证往往需要很多测试用例,测试套件就是针对一组相关测试用例进行环境配置的事件机制// 用法: 先定义环境类,继承于 testing::Test 基类,重写两个静态函数 SetUpTestCase/TearDownTestCase 进行环境的配置和清理class HashTestEnv1 : public testing::Test {public: static void SetUpTestCase() { std::cout << "环境1第一个TEST之前调用\n"; } static void TearDownTestCase() { std::cout << "环境1最后一个TEST之后调用\n"; }
public: std::unordered_map<std::string, std::string> dict;};
// 注意,测试套件使用的不是TEST了,而是TEST_F,而第一个参数名称就是测试套件环境类名称// main函数中不需要再注册环境了,而是在TEST_F中可以直接访问类的成员变量和成员函数TEST_F(HashTestEnv1, insert_test) { std::cout << "环境1,中间insert测试\n"; dict.insert(std::make_pair("Hello", "你好")); dict.insert(std::make_pair("hello", "你好")); dict.insert(std::make_pair("雷吼", "你好")); auto it = dict.find("hello"); ASSERT_NE(it, dict.end());}
TEST_F(HashTestEnv1, sizeof) { std::cout << "环境1,中间size测试\n"; ASSERT_GT(dict.size(), 0);}
int main(int argc, char *argv[]) { testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();}xxxxxxxxxx[==========] Running 2 tests from 1 test case.[----------] Global test environment set-up.[----------] 2 tests from HashTestEnv1环境1第⼀个TEST之前调⽤[ RUN ] HashTestEnv1.insert_test环境1,中间insert测试[ OK ] HashTestEnv1.insert_test (0 ms)[ RUN ] HashTestEnv1.sizeof环境1,中间size测试event.cpp:81: FailureExpected: (dict.size()) > (0), actual: 0 vs 0[ FAILED ] HashTestEnv1.sizeof (0 ms)环境1最后⼀个TEST之后调⽤[----------] 2 tests from HashTestEnv1 (0 ms total)[----------] Global test environment tear-down[==========] 2 tests from 1 test case ran. (1 ms total)[ PASSED ] 1 test.[ FAILED ] 1 test, listed below:[ FAILED ] HashTestEnv1.sizeof1 FAILED TEST3.3.3TestCase事件
如果我们每个测试都需要在当前测试开始时去初始化环境,在当前测试结束时清理环境,也就是说每个测试用到的环境是独立的,我们针对⼀个个测试⽤例。测试⽤例的事件机制的创建和测试套件的基本⼀样,不同地⽅在于测试⽤例实现的两个函数分别是 SetUp 和 TearDown , 这两个函数也不是静态函数: SetUp()函数是在⼀个测试⽤例的开始前执⾏ TearDown()函数是在⼀个测试⽤例的结束后执⾏ 也就是说,在TestSuite/TestCase事件中,每个测试⽤例,虽然它们同⽤同⼀个事件环境类,可以访问其中的资源,但是本质上每个测试⽤例的环境都是独⽴的,这样我们就不⽤担⼼不同的测试⽤例之间会有数据上的影响了,保证所有的测试⽤例都使⽤相同的测试环境进⾏测试。
xxxxxxxxxx
// TestCase: 测试用例的单元测试,即针对每一个测试用例都使用独立的测试环境数据进行测试// 概念: 它是针对测试用例进行环境配置的一种事件机制// 用法: 先定义环境类,继承于 testing::Test 基类,在环境类内重写SetUp/TearDown接口class HashTestEnv2 : public testing::Test {public: static void SetUpTestCase() { std::cout << "环境2第一个TEST之前被调用,进行总体环境配置\n"; } static void TearDownTestCase() { std::cout << "环境2最后一个TEST之后被调用,进行总体环境清理\n"; } virtual void SetUp() override { std::cout << "环境2测试前:提前准备数据!!\n"; dict.insert(std::make_pair("bye", "再见")); dict.insert(std::make_pair("see you", "再见")); } virtual void TearDown() override { std::cout << "环境2测试结束后:清理数据!!\n"; dict.clear(); }
public: std::unordered_map<std::string, std::string> dict;};
TEST_F(HashTestEnv2, insert_test) { std::cout << "环境2,中间测试\n"; dict.insert(std::make_pair("hello", "你好")); ASSERT_EQ(dict.size(), 3);}
TEST_F(HashTestEnv2, size_test) { std::cout << "环境2,中间size测试\n"; auto it = dict.find("hello"); ASSERT_EQ(it, dict.end()); ASSERT_EQ(dict.size(), 2);}
int main(int argc, char *argv[]) { testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS();}xxxxxxxxxx[==========] Running 2 tests from 1 test case.[----------] Global test environment set-up.[----------] 2 tests from HashTestEnv2环境2第⼀个TEST之前被调⽤,进⾏总体环境配置[ RUN ] HashTestEnv2.insert_test环境2测试前:提前准备数据!!环境2,中间测试环境2测试结束后:清理数据!![ OK ] HashTestEnv2.insert_test (1 ms)[ RUN ] HashTestEnv2.size_test环境2测试前:提前准备数据!!环境2,中间size测试环境2测试结束后:清理数据!![ OK ] HashTestEnv2.size_test (0 ms)环境2最后⼀个TEST之后被调⽤,进⾏总体环境清理[----------] 2 tests from HashTestEnv2 (1 ms total)[----------] Global test environment tear-down[==========] 2 tests from 1 test case ran. (1 ms total)[ PASSED ] 2 tests.四.spdlog的介绍与二次封装
spdlog 是⼀个⾼性能、超快速、零配置的 C++ ⽇志库,它旨在提供简洁的 API 和丰富的功能,同时保持⾼性能的⽇志记录。它⽀持多种输出⽬标、格式化选项、线程安全以及异步⽇志记录。以下是对 spdlog 的详细介绍和使⽤⽅法。 github源码链接: https://github.com/gabime/spdlog
4.1安装
命令安装:
xxxxxxxxxxdev@dev-host:~/workspace/spdlog$ sudo apt-get install libspdlog-dev源码安装:
xxxxxxxxxxdev@dev-host:~/workspace/spdlog$ git clone https://github.com/gabime/spdlog.gitdev@dev-host:~/workspace/spdlog$ cd spdlog/dev@dev-host:~/workspace/spdlog$ mkdir build && cd builddev@dev-host:~/workspace/spdlog$ cmake -DCMAKE_INSTALL_PREFIX=/usr ..dev@dev-host:~/workspace/spdlog$ make && sudo make install4.2使用
4.2.1头文件包含
xxxxxxxxxx4.2.2日志输出等级枚举
xxxxxxxxxxnamespace level{ enum level_enum : int { trace = SPDLOG_LEVEL_TRACE, debug = SPDLOG_LEVEL_DEBUG, info = SPDLOG_LEVEL_INFO, warn = SPDLOG_LEVEL_WARN, err = SPDLOG_LEVEL_ERROR, critical = SPDLOG_LEVEL_CRITICAL, off = SPDLOG_LEVEL_OFF, n_levels };}4.2.3日志输出格式自定义
xxxxxxxxxxlogger->set_pattern("%Y-%m-%d %H:%M:%S [%t] [%-7l] %v");%t - 线程ID(Thread ID)。%n - ⽇志器名称(Logger name)。%l - ⽇志级别名称(Level name),如 INFO, DEBUG, ERROR 等。%v - ⽇志内容(message)。%Y - 年(Year)。%m - ⽉(Month)。%d - ⽇(Day)。%H - ⼩时(24-hour format)。%M - 分钟(Minute)。%S - 秒(Second)。4.2.4 日志记录类
⽇志记录器类是spdlog中⽤于进⾏⽇志输出的类,内部定义了各种不同等级⽇志的输出接⼝,同时,也可以在该类中设置⽇志的输出格式以及输出级别等基础配置。
xxxxxxxxxxnamespace spdlog { class logger { public: // 构造函数 logger(std::string name); logger(std::string name, sink_ptr single_sink); logger(std::string name, sinks_init_list sinks); // 日志级别设置 void set_level(level::level_enum log_level); // 格式化设置 void set_formatter(std::unique_ptr<formatter> f); void set_pattern(std::string pattern, pattern_time_type time_type = pattern_time_type::local); // 日志输出方法(模板函数) template<typename... Args> void trace(fmt::format_string<Args...> fmt, Args &&...args); template<typename... Args> void debug(fmt::format_string<Args...> fmt, Args &&...args); template<typename... Args> void info(fmt::format_string<Args...> fmt, Args &&...args); template<typename... Args> void warn(fmt::format_string<Args...> fmt, Args &&...args); template<typename... Args> void error(fmt::format_string<Args...> fmt, Args &&...args); template<typename... Args> void critical(fmt::format_string<Args...> fmt, Args &&...args); // 刷新日志 void flush(); // 策略刷新:触发指定等级日志的时候立即刷新日志的输出 void flush_on(level::level_enum log_level); };}
// 使用示例-{}即为占位符logger->debug("{} 的年龄是: {}", "xiaoming", 18);4.2.5异步日志记录类
为了异步记录⽇志,可以使⽤ spdlog::async_logger ,其总体的常规操作与同步⽇志器并⽆区别,区别仅在于⽇志数据的写⼊⽅式有所不同,异步⽇志器的使⽤会伴随创建⼀个异步线程池(默认只有⼀个线程)进⾏⽇志的实际写⼊操作。
xxxxxxxxxxclass async_logger final : public logger {public: async_logger(std::string logger_name, sinks_init_list sinks_list, std::weak_ptr<details::thread_pool> tp, async_overflow_policy overflow_policy = async_overflow_policy::block); async_logger(std::string logger_name, sink_ptr single_sink, std::weak_ptr<details::thread_pool> tp, async_overflow_policy overflow_policy = async_overflow_policy::block);};
// 异步日志输出需要异步工作线程的支持,这里是线程池类class SPDLOG_API thread_pool {public: thread_pool(size_t q_max_items, size_t threads_n, std::function<void()> on_thread_start, std::function<void()> on_thread_stop); thread_pool(size_t q_max_items, size_t threads_n, std::function<void()> on_thread_start); thread_pool(size_t q_max_items, size_t threads_n);};
// 获取线程池std::shared_ptr<spdlog::details::thread_pool> thread_pool() { return details::registry::instance().get_tp();}
// 默认线程池的初始化接口inline void init_thread_pool(size_t q_size, size_t thread_count);
// 使用示例auto async_logger = spdlog::async_logger_mt("async_logger", "logs/async_log.txt");async_logger->info("This is an asynchronous info message");4.2.6日志记录器工厂
⽇志器⼯⼚是⽤于快速创建⽇志器对象的⼯⼚类,spdlog中默认提供了两种不同的⽇志器⼯⼚类,⼀种是同步⽇志器⼯⼚(默认),⼀种是异步⽇志器⼯⼚,⼯⼚的选择通过⽇志器创建函数模板的模板参数进⾏设置。
xxxxxxxxxx// 异步工厂别名using async_factory = async_factory_impl<async_overflow_policy::block>;
// 创建异步日志器的模板函数template<typename Sink, typename... SinkArgs>inline std::shared_ptr<spdlog::logger> create_async( std::string logger_name, SinkArgs &&...sink_args);
// 创建一个彩色输出到标准输出的日志记录器,默认工厂创建同步日志记录器template<typename Factory = spdlog::synchronous_factory>std::shared_ptr<logger> stdout_color_mt( const std::string &logger_name, color_mode mode = color_mode::automatic);
// 标准错误输出的彩色日志记录器template<typename Factory = spdlog::synchronous_factory>std::shared_ptr<logger> stderr_color_mt( const std::string &logger_name, color_mode mode = color_mode::automatic);
// 指定文件的日志记录器template<typename Factory = spdlog::synchronous_factory>std::shared_ptr<logger> basic_logger_mt( const std::string &logger_name, const filename_t &filename, bool truncate = false, const file_event_handlers &event_handlers = {});
// 循环文件日志记录器(按文件大小轮转)template<typename Factory = spdlog::synchronous_factory>std::shared_ptr<logger> rotating_logger_mt( const std::string &logger_name, const filename_t &filename, size_t max_file_size, size_t max_files, bool rotate_on_open = false);4.2.7日志落地类
⽇志落地类,负责决定将⽇志数据写⼊到哪些设备中,在spdlog中,实现了⾮常多的落地⽅向,这⾥贴出了标准输出,普通⽂件,滚动⽂件等⼏种常⽤对象的创建⽅式。 除此之外,还可以在该类中进⼀步细化设置⽇志的输出格式,输出等级等配置(或者说其实spdlog中有很多地⽅都可以设置⽇志输出等级和输出格式,但是实际都会归总到⽇志落地类中进⾏最后的⽇志格式组织,以及判断是否该输出等操作)。
xxxxxxxxxxnamespace spdlog {namespace sinks {
class SPDLOG_API sink {public: virtual ~sink() = default; virtual void log(const details::log_msg &msg) = 0; virtual void flush() = 0; virtual void set_pattern(const std::string &pattern) = 0; virtual void set_formatter(std::unique_ptr<spdlog::formatter> sink_formatter) = 0; void set_level(level::level_enum log_level);};
// 标准输出日志落地类using stdout_sink_mt;using stderr_sink_mt;using stdout_color_sink_mt;using stderr_color_sink_mt;
// 滚动日志文件 - 超过一定大小则自动重新创建新的日志文件sink_ptr rotating_file_sink(filename_t base_filename, std::size_t max_size, std::size_t max_files, bool rotate_on_open = false, const file_event_handlers &event_handlers = {});
using rotating_file_sink_mt = rotating_file_sink<std::mutex>;
// 普通的文件落地对象创建接口sink_ptr basic_file_sink(const filename_t &filename, bool truncate = false, const file_event_handlers &event_handlers = {});
using basic_file_sink_mt = basic_file_sink<std::mutex>;
// 网络和其他存储落地类using kafka_sink_mt = kafka_sink<std::mutex>;using mongo_sink_mt = mongo_sink<std::mutex>;using tcp_sink_mt = tcp_sink<std::mutex>;using udp_sink_mt = udp_sink<std::mutex>;
// 其他 sink 类型...
} // namespace sinks} // namespace spdlog4.2.8全局配置接⼝
可以通过⼀些spdlog命名空间下的全局接⼝,对全局的⽇志输出进⾏配置(⼀旦配置则对全局⽣效)。
xxxxxxxxxx//输出等级设置接⼝void set_level(level::level_enum log_level);//⽇志刷新策略-每隔N秒刷新⼀次void flush_every(std::chrono::seconds interval)//⽇志刷新策略-触发指定等级⽴即刷新void flush_on(level::level_enum log_level);4.2.9记录日志
使⽤⽇志记录器记录不同级别的⽇志:
xxxxxxxxxxlogger->trace("This is a trace message");logger->debug("This is a debug message");logger->info("This is an info message");logger->warn("This is a warning message");logger->error("This is an error message");logger->critical("This is a critical message");4.2.10使用示例
根据上面的相关接口介绍,我们可以得到如下的使用流程: 1.设置日志为同步/异步属性 2.设置日志的输出目标:标准输出/标准错误输出/文件输出/循环文件输出 3.设置日志的输出格式 4.设置日志的最低输出级别 5.输出日志 所以我们可以得到如下的一个使用示例:
xxxxxxxxxx
int main(){ // 标准同步输出 // auto logger = spdlog::stdout_color_st("logger"); // 标准异步输出 // auto logger = spdlog::stdout_color_mt<spdlog::async_factory>("logger"); // 标准文件同步输出 // auto logger = spdlog::basic_logger_st("logger", "logs/log.txt"); // 循环文件同步输出 auto logger = spdlog::rotating_logger_mt("logger", "logs/log.txt", 1024, 3, false); // 设置日志输出格式 logger->set_pattern("[%Y-%m-%d] [%H:%M:%S] [%-7l] %v"); // 设置日志输出最低级别 logger->set_level(spdlog::level::info); // 输出测试日志 logger->info("This is an info log"); return 0;}xxxxxxxxxx//makefilelogger:stdout.cc g++ $^ -o $@ -lpthread -lspdlog -lfmt
clean: rm -f logger读者可自行去除注释或增加注释去运行代码。需要特别说明的是循环文件输出的最后的bool参数设置,有兴趣的读者可以自行进行了解下,问下ai很容易就能了解他们的区别了。因为我们封装的时候只关心是否同步或异步,输出方向是标准输出还是文件输出,以及日志输出格式和日志输出最低级别。所以我们这里不再深入介绍。
4.3二次封装
我们在写客户端是是通过宏的方式去使用日志的,所以这里我们也是最终封装成可以通过宏进行日志输出的方式: 设计思路如下: 1.定义日志设置的结构体,此结构体中包含同步/异步开启,输出方向,日志输出格式及日志输出最低级别 2.在使用日志前通过该结构体对全局日志对象进行初始化 3.封装日志输出宏 封装结果如下:
xxxxxxxxxx//limelog.h// 声明命名空间namespace limelog { // 声明⽇志配置结构体 struct log_settings { // 是否启⽤异步⽇志 bool async = false; // ⽇志输出等级: 1-debug;2-info;3-warn;4-error; 6-off int level = 1; // ⽇志输出格式 [%H:%M:%S][%-7l]: %v std::string format = "[%H:%M:%S][%-7l]: %v"; // ⽇志输出⽬标 stdout std::string path = "stdout"; }; // 声明全局⽇志器 extern std::shared_ptr<spdlog::logger> g_logger; // 声明全局⽇志器初始化接⼝ extern void limelog_init(const log_settings &settings = log_settings()); // 封装⽇志输出宏 }##VA_ARGS表示是一个可变参数,我们使用封装日志时是这样的ERR("{}1231",arg),如果没有额外参数,##VA_ARGS会自动去掉它前面的那个,避免出现宏替换后limelog::g_logger->error(FMT_PREFIX + fmt, FILE, LINE,)这样的情况。
xxxxxxxxxx//limelog.cc
namespace limelog { std::shared_ptr<spdlog::logger> g_logger = nullptr; //初始化日志器 void limelog_init(const log_settings &settings){ //当g_logger为空时,才进行初始化 if (!g_logger) { //1-2-3.判断是否异步-判断日志输出方向-创建日志器 if (settings.async) { //异步日志 if (settings.path == "stdout") { g_logger = spdlog::stdout_color_mt<spdlog::async_factory>("limelog"); } else { g_logger = spdlog::basic_logger_mt<spdlog::async_factory>("limelog", settings.path); } } else { //同步日志 if (settings.path == "stdout") { g_logger = spdlog::stdout_color_mt("limelog"); } else { g_logger = spdlog::basic_logger_mt("limelog", settings.path); } } } //4-5.设置日志输出格式与日志输出最低级别 g_logger->set_pattern(settings.format); g_logger->set_level(spdlog::level::level_enum(settings.level)); }}

评论(已关闭)
评论已关闭